From Pattern Matching to Prajna: Grokking, Gurukulas, and the Emergence of Intelligence
- Anaadi Foundation
- Feb 10
- 4 min read

In the contemporary landscape of Artificial Intelligence, "grokking" refers to a sudden, dramatic shift in a neural network’s performance. After thousands of iterations of seemingly stagnant progress—where the model simply memorizes data—it suddenly "clicks." It moves beyond rote pattern matching to discover the underlying mathematical logic, achieving near-perfect generalization. This phenomenon is a technical echo of a process the Indian tradition has understood for millennia: the transition from shravana (hearing/input) to prajna (transformative wisdom).
However, a fundamental tension exists between how true intelligence emerges and how it is managed in the modern, structured, timetabled classroom. To understand why intelligence often remains elusive in mainstream schooling, we must compare the mechanics of grokking with the pedagogical depth of the Gurukulam.
The Mechanics of Grokking
Grokking occurs when a system is given enough time and "weight" to move past the superficial. In the early stages of training, a model uses its parameters to store specific examples—much like a student cramming for a test. It is only through extended, often unstructured-looking "overtraining" that the model realizes it is more efficient to learn the rule than to memorize the instances.
This transition requires a state of "immersion." If the training process were interrupted every 45 minutes to switch from mathematics to history, the model would likely never find the deep structural insights required for grokking. It needs the persistence of a single focus to reorganize its internal architecture. |
Why the Timetabled Classroom Fails the Grokking Test
The modern classroom is designed for industrial efficiency, not the emergence of intelligence. Its structured timetable is the antithesis of the environment needed for a breakthrough.
The Problem of Context Switching: Intelligence emerges when the mind is allowed to enter a "flow state." The 40-minute period is a hard stop that resets the cognitive "weights." Just as the mind begins to seek the deeper logic of a problem, the bell rings, and the student must purge that context to focus on a different subject.
Memorization vs. Generalization: Mainstream systems incentivize "memorization for the exam." In AI terms, this is a model that never groks because it is never pushed to generalize; it is rewarded for outputting specific, pre-defined answers.
Lack of Synthesis: Structure often prevents the "cross-pollination" of ideas. True intelligence is the ability to apply a principle from one domain to an entirely new one. By walling off subjects, we prevent the "sudden click" where a student realizes that the logic of a sentence is the logic of an equation.
The Gurukula Vidyarthi: Learning as Living
The Gurukula system is built on this very principle of sustained immersion. A Vidyarthi (seeker of knowledge) does not merely attend classes; they live the subject. This environment mirrors the "high-density" data environment required for grokking.
Sustained Focus (Nididhyasana): Unlike a school where subjects are fragmented, the Vidyarthi engages in deep contemplation. Whether it is mastering the intricacies of Vyakarana (grammar) or the logic of Nyaya, the learning is not bound by a bell.
Contextual Integration: In a Gurukula, intelligence emerges because knowledge is not siloed. The student sees the mathematical precision of Ganita reflected in the rhythm of Chandas (prosody) and the movement of the stars in Jyotisha.
The Role of the Guru: The Guru provides the "objective function"—the guidance that ensures the student doesn't just "overfit" or become pedantic, but moves toward Viveka (discernment).
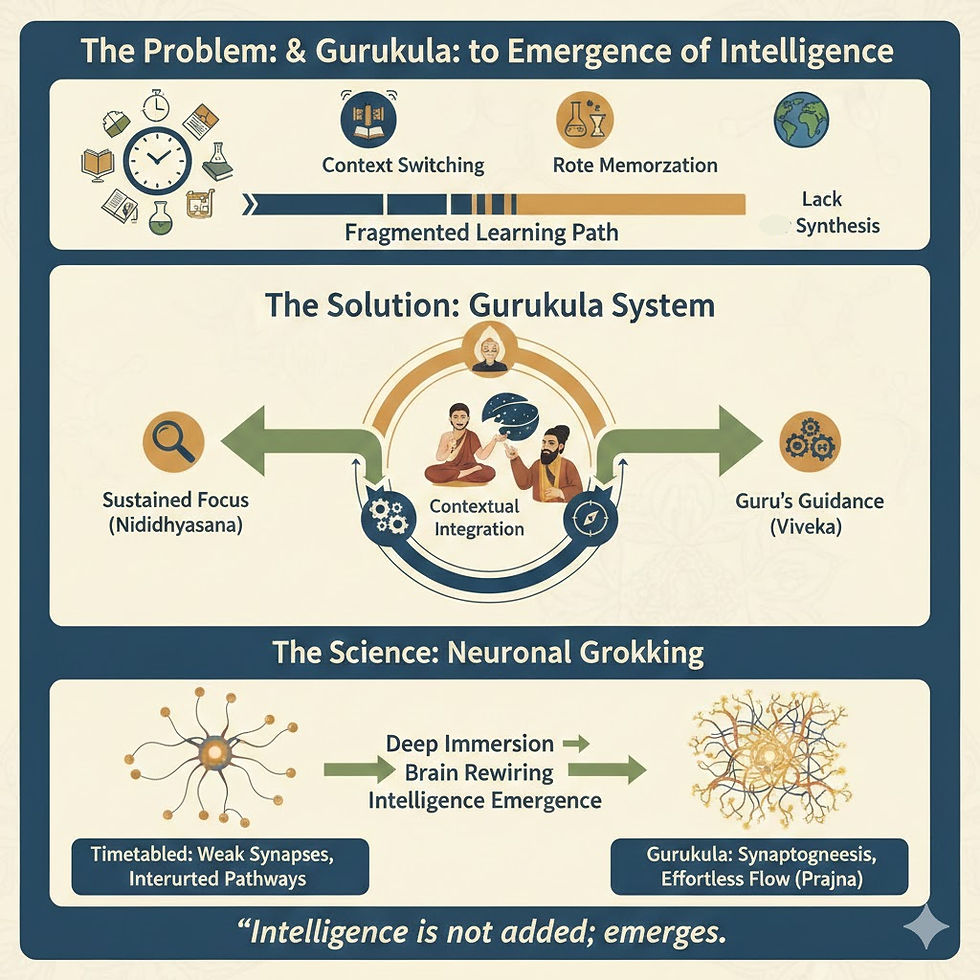
The Biological "Grokking": Neuronal Plasticity in the Gurukula
Biologically, intelligence is not stored in individual neurons but emerges through the strength and complexity of the synaptic connections between them. Each time a Vidyarthi engages in deep, focused study, specific neural pathways are activated. In a fragmented, timetabled environment, these pathways are frequently interrupted, preventing the "long-term potentiation" (strengthening of synapses) required for deep mastery. However, in a Gurukula-style immersion, the brain is allowed to stay in a state of high-intensity firing within a single domain. This sustained activation encourages synaptogenesis—the birth of new connections—and the pruning of irrelevant data.
As these neuronal networks become increasingly dense and interconnected, the brain undergoes a phase transition similar to grokking. It shifts from heavy cognitive lifting to a state of effortless "flow," where the biological architecture of the brain has literally rewired itself to embody the knowledge, allowing intelligence to emerge as a spontaneous, holistic realization rather than a forced recall of facts. |
The Emergence of Intelligence
Intelligence is not an additive process; it is an emergent one. You cannot build it brick by brick in a linear fashion. Instead, you create the conditions—high-quality input, deep immersion, and the freedom to struggle—until the "click" happens.
While the "grokking" of an AI is a mathematical miracle of optimization, the "grokking" of a Vidyarthi is the awakening of Buddhi (intellect). It requires a departure from the rigid, artificial structures of modern schooling in favor of an environment that respects the nonlinear, immersive nature of the human mind. To truly learn is to grok, and to grok, one must be free from the constraints of the clock.



Comments